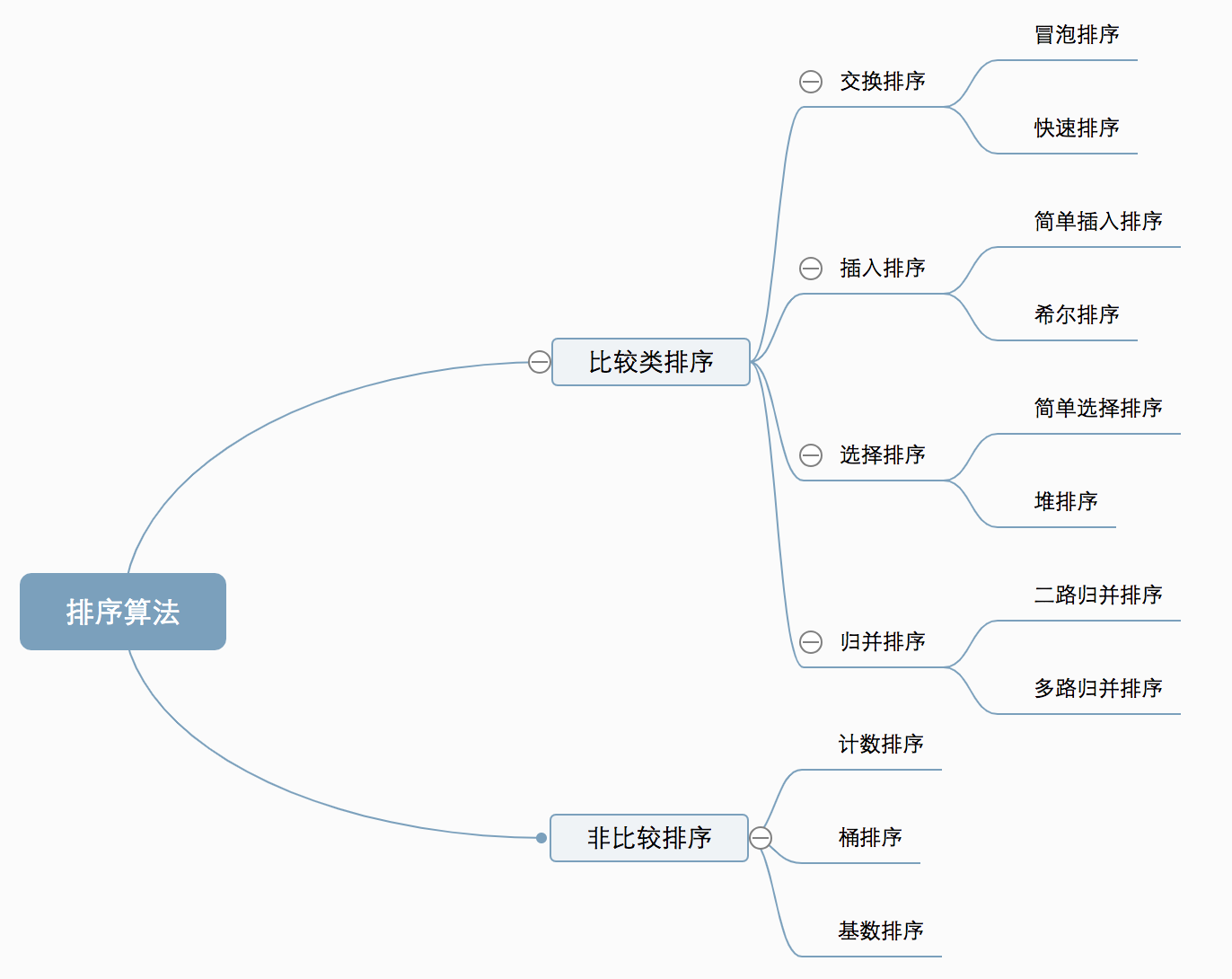
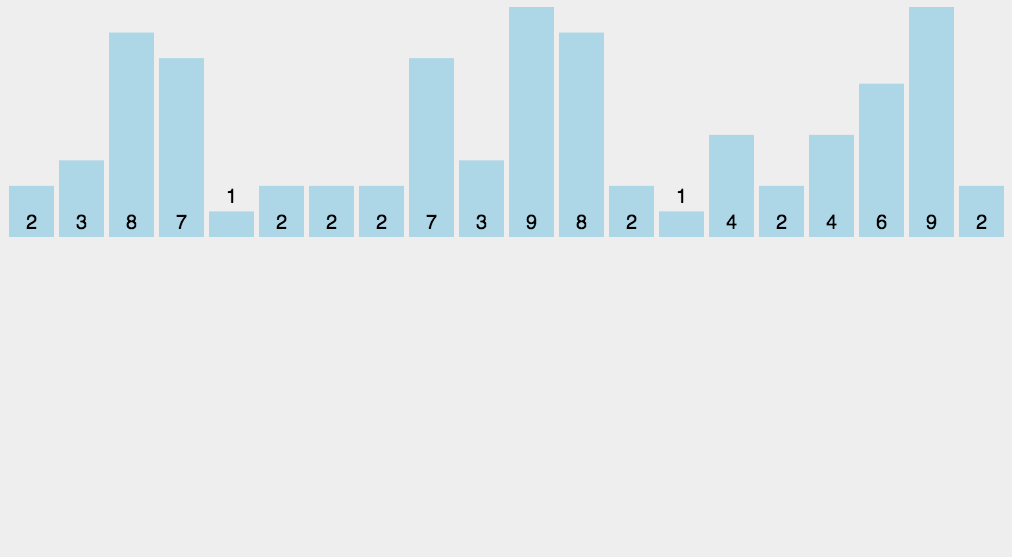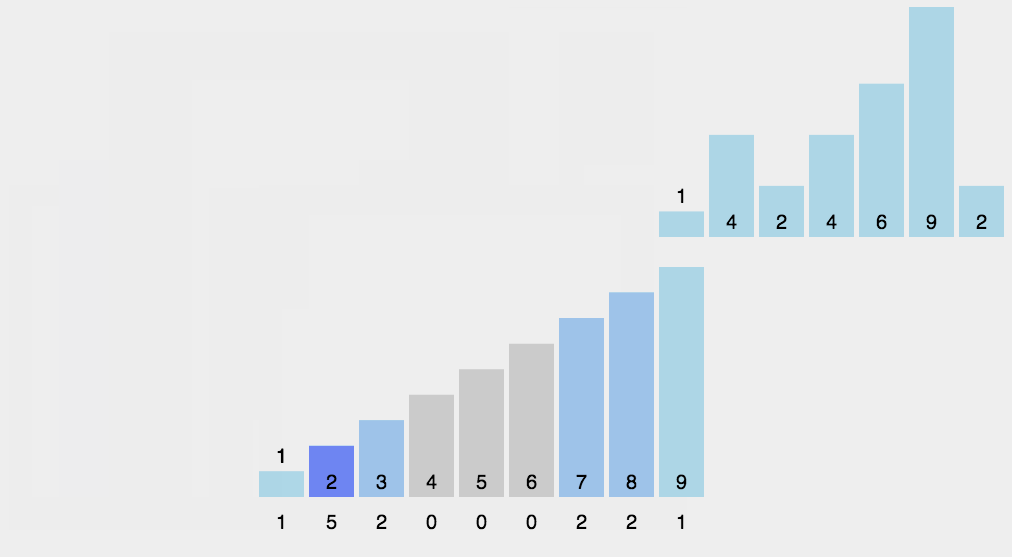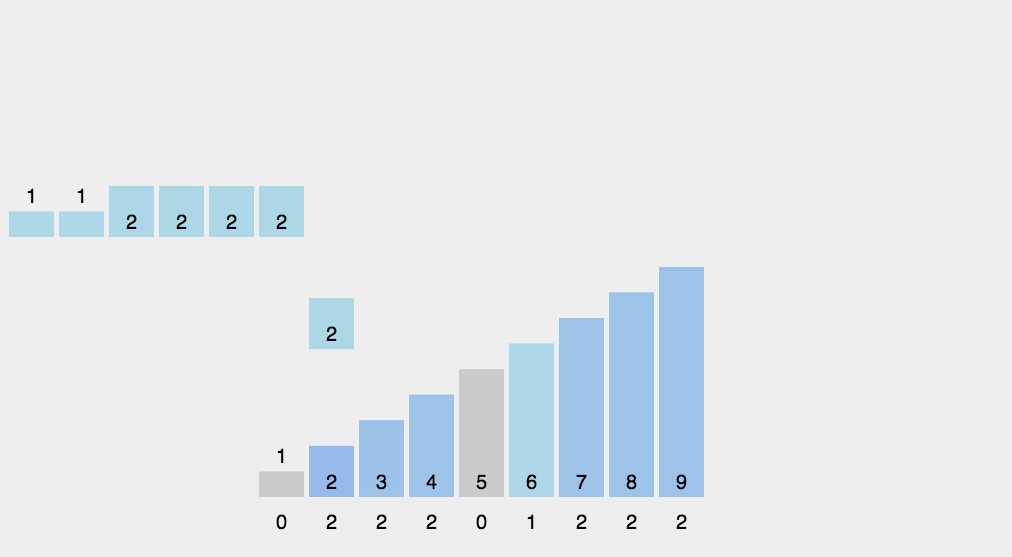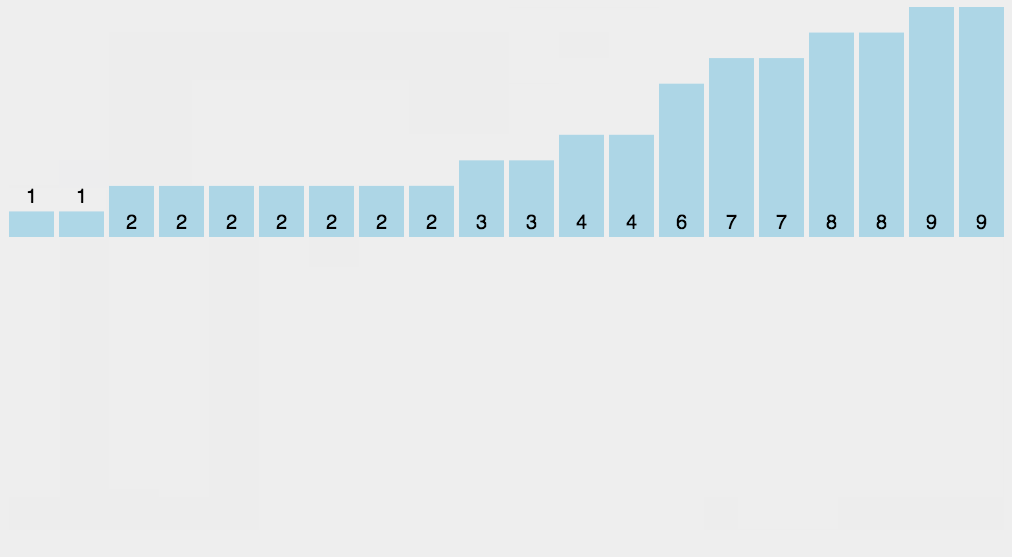voidbubbleSort(vector<int> &arr){ int len = arr.size(); for (int i = 0; i < len-1; i++) { for (int j = 0; j < len-1-i; j++) { if (arr[j] > arr[j+1]) swap(arr[j], arr[j+1]); } } }
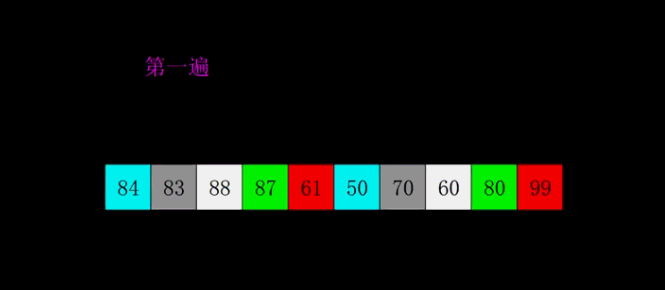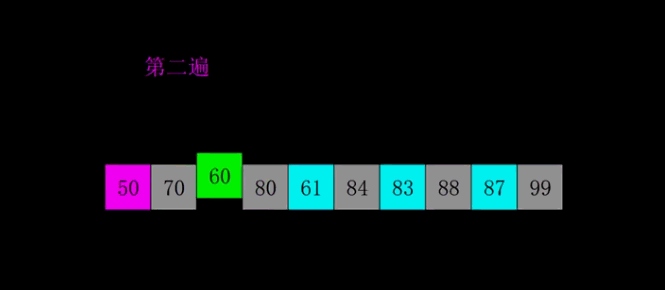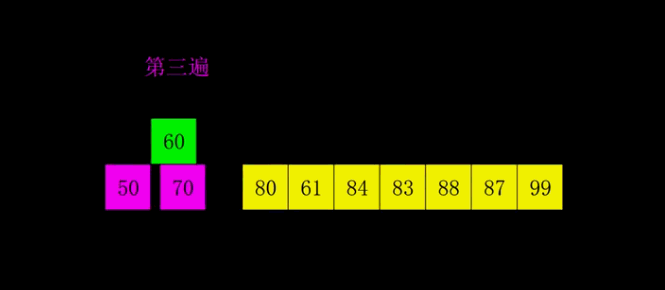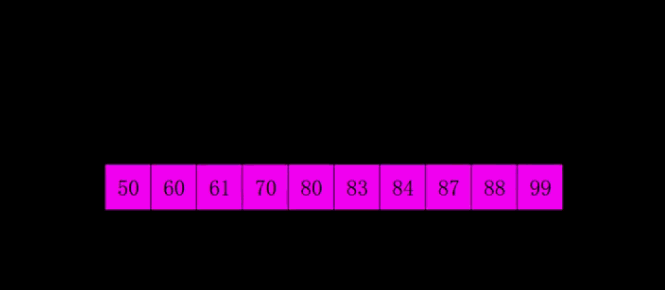
第 i 趟排序 (i=1,2,3…n-1) 开始时,当前有序区和无序区分别为 R[1..i-1]和 R(i..n)。该趟排序从当前无序区中 - 选出关键字最小的记录 R[k],将它与无序区的第 1 个记录 R 交换,使 R[1..i]和 R[i+1..n)分别变为记录个数增加 1 个的新有序区和记录个数减少 1 个的新无序区;
n-1 趟结束,数组有序化了。
2.2 动图演示
2.3 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voidselectionSort(vector<int> &arr){ int len = arr.size(); int minIdx; for (int i = 0; i < len-1; i++) { minIdx = i; for (int j = i+1; j < len; j++) { if (arr[j] < arr[minIdx]) minIdx = j; }
/* 数组本身就可以表示堆(完全二叉树) */ voidheapSort(vector<int> &arr) { int n = arr.size(); /* 构建大顶堆 */ for (int i = n / 2 - 1; i >= 0; i--) { /* 从第一个非叶子结点从下至上,从右至左调整结构 */ adjustHeap(arr, i, n); }
/* 将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端 */ for (int i = n - 1; i > 0; i--) { swap(arr[0], arr[i]); /* 重新对堆进行调整 */ adjustHeap(arr, 0, i); } }
voidadjustHeap(vector<int> &arr, int i, int n) { int child; int temp; for (temp = arr[i]; 2 * i + 1 < n; i = child) { child = 2 * i + 1; // 如果有右孩子,且右孩子大于左孩子 if (child + 1 < n && arr[child] < arr[child + 1]) { child++; } // 如果父节点大于任何一个孩子的值,则直接跳出 if (temp >= arr[child]) { break; } // 把较大的孩子往上移动,替换它的父节点 arr[i] = arr[child]; } arr[i] = temp; }
反向填充目标数组:将每个元素 i 放在新数组的第 C(i) 项,每放一个元素就将 C(i) 减去 1。
8.2 动图演示
8.3 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13
voidcountingSort(vector<int> &arr, int maxValue){ int t = 0; vector<int> count(maxValue+1, 0); /* 计数 */ for (int i = 0; i < arr.size(); i++) count[arr[i]]++;
/* 重建 */ for (int i = 0; i <= maxValue; i++) { while(count[i]--) arr[t++] = i; } }
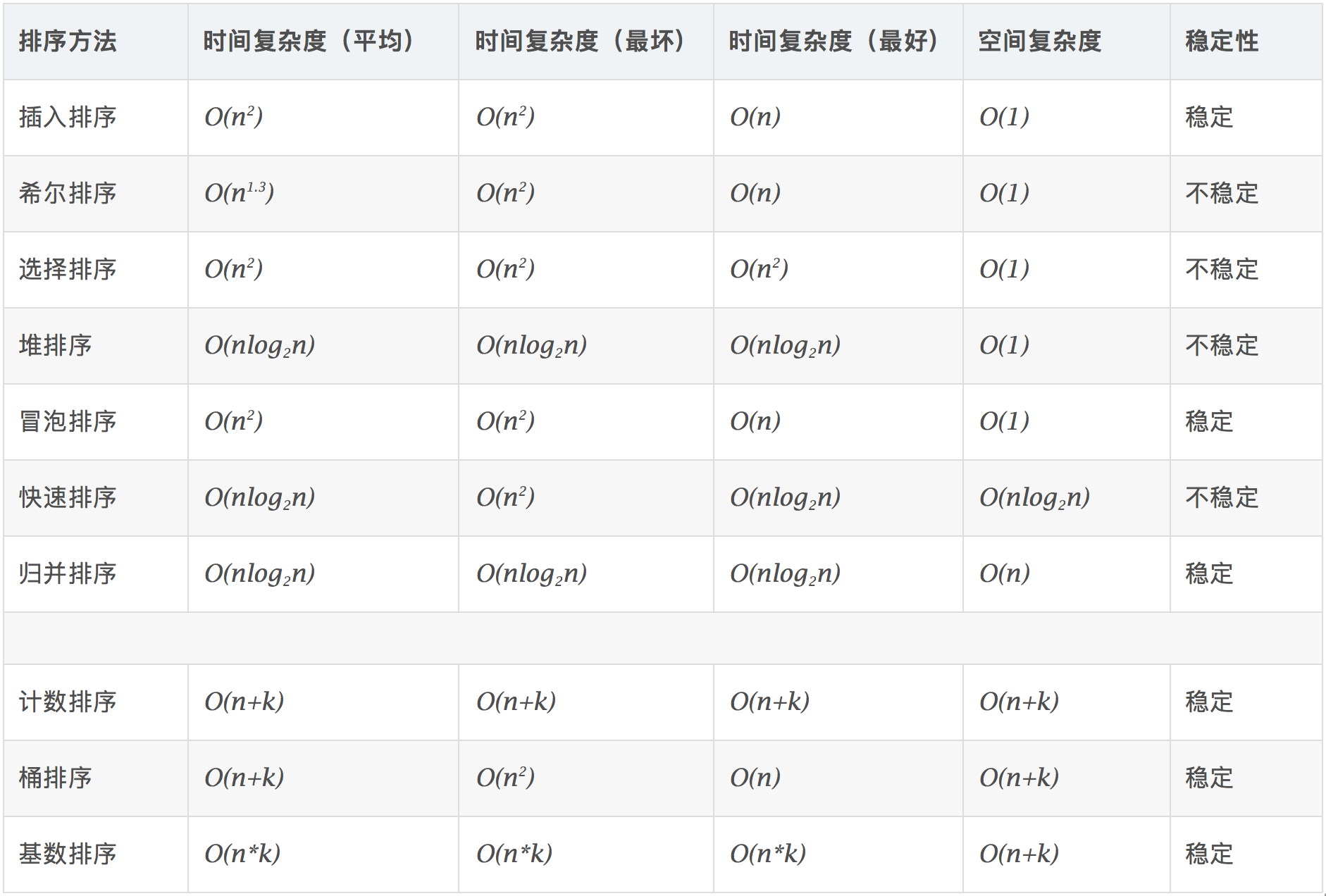
8.4 算法分析
计数排序是一个稳定的排序算法。当输入的元素是 n 个 0 到 k 之间的整数时,时间复杂度是 O(n+k),空间复杂度也是 O(n+k),其排序速度快于任何比较排序算法。当 k 不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
voidradixSort(vector<int> &arr) { int count = 1; /* 用于判断是否继续比较高位 */ int mod = 10, dev = 1; int len = arr.size(); vector<queue<int>> radix(10, queue<int>());
while(count) { count = 0; /* 放到桶中 */ for (int i = 0; i < len; i++) { radix[(arr[i]%mod)/dev].push(arr[i]); if (arr[i]/mod > 0) ++count; } mod *= 10; dev *= 10;
/* 重建 arr */ int t = 0; for (int i = 0; i < 10; i++) { while(!radix[i].empty()) { arr[t++] = radix[i].front(); radix[i].pop(); } } } }
10.4 算法分析
基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要 O(n) 的时间复杂度,而且分配之后得到新的关键字序列又需要 O(n) 的时间复杂度。假如待排数据可以分为 d 个关键字,则基数排序的时间复杂度将是 O(d*2n) ,当然 d 要远远小于 n,因此基本上还是线性级别的。
基数排序的空间复杂度为 O(n+k),其中 k 为桶的数量。一般来说 n>>k,因此额外空间需要大概 n 个左右。
voidbubbleSort(vector<int> &arr){ int len = arr.size(); for (int i = 0; i < len-1; i++) { for (int j = 0; j < len-1-i; j++) { if (arr[j] > arr[j+1]) swap(arr[j], arr[j+1]); } } }
voidselectionSort(vector<int> &arr){ int len = arr.size(); int minIdx; for (int i = 0; i < len-1; i++) { minIdx = i; for (int j = i+1; j < len; j++) { if (arr[j] < arr[minIdx]) minIdx = j; }
if (minIdx != i) swap(arr[minIdx], arr[i]); } }
voidinsertionSort(vector<int> &arr){ int len = arr.size(); int currVal, currIdx; for (int i = 1; i < len; i++) { currIdx = i; currVal = arr[i]; while(currIdx > 0 && currVal < arr[currIdx-1]) { arr[currIdx] = arr[currIdx-1]; currIdx--; } arr[currIdx] = currVal; } }
voidshellSort(vector<int> &arr){ int len = arr.size(); int currVal, currIdx; /* gap 就是上面的 t1, t2, ... , tk,也是动图中两个相同颜色方框的间距 */ for (int gap = len/2; gap > 0; gap = gap/2) { /* 希尔排序是基于插入排序,下面的过程和插入排序一致, * 通过 gap 实现了分组插入排序 * 这里和动图演示的不一样,动图是分组执行,实际操作是多个分组交替执行 */ for(int i = gap; i < len; i++) { currIdx = i; currVal = arr[i]; while(currIdx-gap >= 0 && currVal < arr[currIdx-gap]) { arr[currIdx] = arr[currIdx-gap]; currIdx -= gap; } arr[currIdx] = currVal; } } }
/* 合并两个有序数组 (l,mid), (mid+1,r) * 下面是借助一个额外数组的合并方法,一般都用此方法 */ voidmerge(vector<int> &arr, int l, int r, int mid){ vector<int> tmp(r-l+1); int i = l, j = mid+1, t = 0; while(i <= mid && j <= r) { if (arr[i] < arr[j]) { tmp[t++] = arr[i++]; } else { tmp[t++] = arr[j++]; } } while(i <= mid) tmp[t++] = arr[i++]; while(j <= r) tmp[t++] = arr[j++];
for (i = l; i <= r; i++) { arr[i] = tmp[i-l]; } }
/* 拆分数组,不能用额外空间,就只有记录左右下标 */ voidmergeSortSplit(vector<int> &arr, int l, int r){ if (l >= r) return; /* 还可拆分就继续分 */ int mid = l + (r-l)/2; /* or l + ((r-l)>>1); 注意 >> 优先级低于 + */ mergeSortSplit(arr, l, mid); mergeSortSplit(arr, mid+1, r); /* 到此就可以保证 (l,mid), (mid+1,r) 这两个数组是有序的了, * 现在要将这两个有序数组合并为一个有序数组 */ merge(arr, l, r, mid); }
/* 对外提供的接口只传入数组 */ voidmergeSort(vector<int> &arr){ int len = arr.size(); if (len > 2) mergeSortSplit(arr, 0, len-1); }
/* 动图中的算法,如果不理解可以点开那个可视化的网页,可以逐步查看 */ intpartition(vector<int> &arr, int l, int r){ int pivot = arr[l]; int bigIdx = l+1; /* 记录第一个大于pivot的值的下标, -1表示不存在 */
voidadjustHeap(vector<int> &arr, int i, int n){ int child; int temp; for (temp = arr[i]; 2 * i + 1 < n; i = child) { child = 2 * i + 1; // 如果有右孩子,且右孩子大于左孩子 if (child + 1 < n && arr[child] < arr[child + 1]) { child++; } // 如果父节点大于任何一个孩子的值,则直接跳出 if (temp >= arr[child]) { break; } // 把较大的孩子往上移动,替换它的父节点 arr[i] = arr[child]; } arr[i] = temp; }
/* 数组本身就可以表示堆(完全二叉树) */ voidheapSort(vector<int> &arr){ int n = arr.size(); /* 构建大顶堆 */ for (int i = n / 2 - 1; i >= 0; i--) { /* 从第一个非叶子结点从下至上,从右至左调整结构 */ adjustHeap(arr, i, n); }
/* 将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端 */ for (int i = n - 1; i > 0; i--) { swap(arr[0], arr[i]); /* 重新对堆进行调整 */ adjustHeap(arr, 0, i); } }
voidcountingSort(vector<int> &arr, int maxValue){ int t = 0; vector<int> count(maxValue+1, 0); /* 计数 */ for (int i = 0; i < arr.size(); i++) count[arr[i]]++;
/* 重建 */ for (int i = 0; i <= maxValue; i++) { while(count[i]--) arr[t++] = i; } }
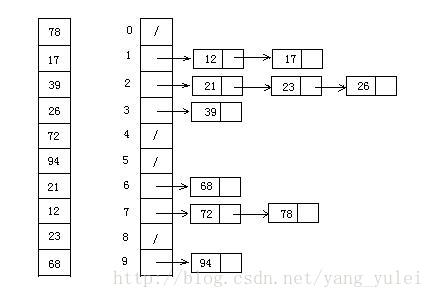
voidbucketSort(vector<int> &arr){ int bucketNum = 10; /* 桶的数量 */ int bucketIndex; vector<vector<int>> bucket(bucketNum, vector<int>());
/* 获取数组的最大值和最小值 */ int maxNum = arr[0], minNum = arr[0]; for (int i = 1; i < arr.size(); i++) { maxNum = max(maxNum, arr[i]); minNum = min(minNum, arr[i]); }
/* 将数据映射到桶中 */ for (int i = 0; i < arr.size(); i++) { bucketIndex = (int)(arr[i] * bucketNum / (maxNum - minNum + 1)); /* 这里可能出现 bucketIndex == bucketNum,需要特殊处理 */ if (bucketIndex == bucketNum) --bucketIndex; bucket[bucketIndex].emplace_back(arr[i]); }
/* 对每个桶中的数据排序,可以选用快排等,这里为了简洁直接调用sort */ for (int i = 0; i < bucketNum; i++) { sort(bucket[i].begin(), bucket[i].end()); }
/* 将各个桶中的数据按顺序取出,得到排序后的数组 * 之所以合并过程不需要再次判断,是因为前面映射函数保证了 * 第 i-1 个桶中的数 < 第 i 个桶中的数 < 第 i+1 个桶中的数 */ int t = 0; for (int i = 0; i < bucketNum; i++) { for (int & v : bucket[i]) arr[t++] = v; } }
voidradixSort(vector<int> &arr){ int count = 1; /* 用于判断是否继续比较高位 */ int mod = 10, dev = 1; int len = arr.size(); vector<queue<int>> radix(10, queue<int>());
while(count) { count = 0; /* 放到桶中 */ for (int i = 0; i < len; i++) { radix[(arr[i]%mod)/dev].push(arr[i]); if (arr[i]/mod > 0) ++count; } mod *= 10; dev *= 10;
/* 重建 arr */ int t = 0; for (int i = 0; i < 10; i++) { while(!radix[i].empty()) { arr[t++] = radix[i].front(); radix[i].pop(); } } } }
voidprintArray(vector<int> &arr){ for (int i = 0; i < arr.size(); i++) cout << arr[i] << ", "; cout << endl; }