
OpenVSwitch-数据结构
常用宏
include/openvswitch/util.h #119
typeof
typeof不是C语言本身的关键词或运算符,它是GCC的一个扩展,作用正如其字面意思,用某种已有东西(变量、函数等)的类型去定义新的变量类型。
1 | typeof(int *)a, b; // 等价于 int *a, *b; |
offsetof
获取结构体TYPE中某个成员MEMBER的偏移量(相对于结构体地址)。
1 | /* /usr/lib/gcc/x86_64-linux-gnu/9/include/stddef.h */ |
OBJECT_OFFSETOF
给定一个指向结构体的指针OBJECT,返回其成员MEMBER的偏移量。
1 |
|
CONTAINER_OF
已知结构体STRUCT中某个成员MEMBER的地址为POINTER,返回该结构体STRUCT的首地址。
1 | /* include/openvswitch/util.h #119 */ |
OBJECT_CONTAINING
已知某个结构体对象中某个成员MEMBER的地址为POINTER,返回该对象的地址。
与CONTAINER_OF类似,只是由STRUCT替换为指向该结构体的指针OBJECT,且OBJECT是否为空无影响,只是用于通过type_of获取结构体类型。
1 |
|
ASSIGN_CONTAINER
同上,已知某个结构体对象中某个成员MEMBER的地址为POINTER,但是将该结构体的地址赋值给OBJECT,返回(void)0。
,逗号运算符的优先级最低!所以这里是先对OBJECT赋值。
1 |
|
INIT_CONTAINER
同上,就多个一个对OBJECT初始化为NULL的操作。
1 |
BUILD_ASSERT_TYPE
编译过程做类型一致性检查。如果POINTER与指定的类型TYPE不匹配的话,会报编译错误。但如果给定的TYPE是void *,则可以与任意类型的POINTER匹配。
- sizeof:
POINTER可以是表达式,所以这里用sizeof来确保表达式不会被执行。 - **(void)**:通过
(void)忽略函数或表达式的值,这里是sizeof的返回值。
1 |
CONST_CAST
将const修饰的指针转为指定TYPE的non-const类型。当指定的类型TYPE与指针POINTER类型不匹配时,编译会有警告。
1 |
|
ovs_assert
当条件不满足时,会报错并输出发生错误的位置信息,用于调试阶段。
1 |
ovs_list
include/openvswitch/list.h
双向链表结构!
1 | struct ovs_list { |
当某个结构体需要实现链表时,只需要将该ovs_list嵌入到结构体中。
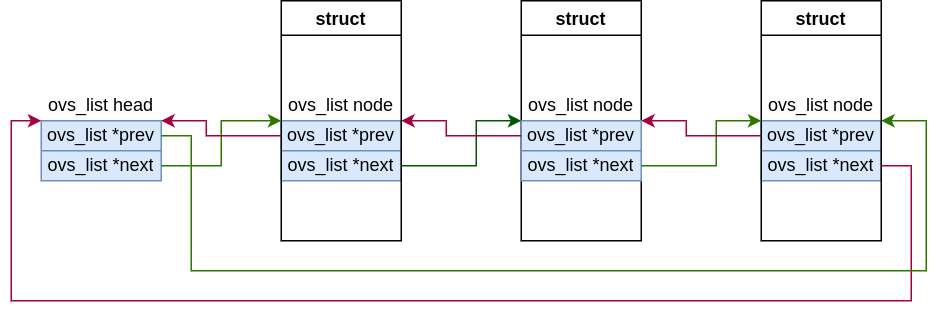
prev/next指向的是struct s中的node,当需要s的地址时,需要通过上面的宏CONTAINER_OF或者OBJECT_CONTAINING。
LIST_FOR_EACH:ITER为结构体的空指针struct s *p = NULL,遍历过程中会指向当前节点;MEMBER为结构体中ovs_list成员的名称node;LIST为链表的头节点(或者任意链表中的任意一个节点),LIST自身不会被遍历到;
1 |
LIST_FOR_EACH_CONTINUE:同上,但ITER有初始值,从当前位置的下一个节点开始遍历。
1 |
LIST_FOR_EACH_REVERSE:与LIST_FOR_EACH类似,但反向遍历。
1 |
一个例子:
- 将该代码放在
ovs源码根目录下,编译时指定头文件路径:gcc test.c -o test -I include。 - 将宏定义展开:
gcc -E -P test.c -o test.i,直接跳转到最后看。
1 |
|
hmap
include/openvswitch/hmap.h
lib/hmap.c
A hash map.
一种哈希桶实现。
- 桶的数量可自动扩容、收缩,且总是
2^n。 - 哈希函数就是
key & mask,这里mask = 2^n-1。 - 通过开链法解决哈希冲突。
- 节点数量为0或1时比较特殊。
将哈希桶的大小设置为
2^n是为了加速。假设桶的大小为len,那么哈希函数就应该为key % len,而当len = 2^n时,key % len == key & (len - 1),相比之下,&操作比%更快。
1 | struct hmap { |
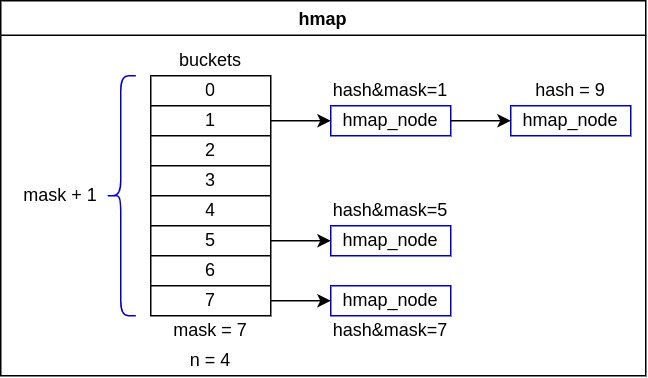
同样,通过hmap得到hmap_node的地址后,需要通过CONTAINER_OF获取对应结构体对象的地址。
常用方法:
1 | void hmap_init(struct hmap *); /* 初始化 */ |
HMAP_FOR_EACH_WITH_HASH:遍历 HMAP 中所有 hash_node->hash 值等于 HASH 的节点,Node实际struct的指针;
根据HASH找到哈希桶所在的下标,然后遍历对应的链表。链表中,有可能不同hash值的节点,这些节点会被跳过。
1 |
|
HMAP_FOR_EACH_IN_BUCKET:同上,但遍历链表时,不会跳过有不同hash值的节点。
1 |
HMAP_FOR_EACH:遍历HMAP中的所有节点。
1 |
HMAP_FOR_EACH_SAFE:遍历HMAP中的所有节点。
与HMAP_FOR_EACH相比,在进行循环条件判断时,会通过NEXT预取下一个节点,这意味着即使在循环过程中将NODE从HMAP中移除,仍然可正确遍历后续节点。
其实如果只是从HMAP中移除,上面的HMAP_FOR_EACH也可以,不过要是还调用了free(NODE),上面的就会导致段错误,或者一些奇怪的值。
1 |
HMAP_FOR_EACH_CONTINUE:可以从中间某个位置(NODE所在位置)开始遍历。
1 |
hmap_insert:向HMAP中插入节点NODE,新节点的哈希值为HASH。
该插入函数在插入节点时不会检查是否已经有同样哈希值的节点,也就是说hmap中可能存在哈希值相同的节点
1 |
|
一个例子:
- 将该代码放在
ovs源码根目录下,编译时指定头文件路径:gcc test.c -o test -I include,hmap.h也需要一点修改才能编译。 - 将宏定义展开:
gcc -E -P test.c -o test.p -I include -I .,直接跳转到最后看。
1 |
|
include/openvswitch/hmap.h 需要将
hmap.c中的实现暂时放到hmap.h中才能正确编译,而且还注释了一些其他外部函数调用。
1 |
|
smap
a map from string to string.
同样是在hmap上进行扩展,该结构的key和value均为字符串,hash由key计算得到。
1 | struct smap { |
simap
A map from strings to unsigned integers.
与smap类似,hash值是由字符串name计算得到,只不过value变为了unsigned int。
1 | struct simap { |
shash
a map from string(char *name) to void *data。
1 | struct shash_node { |
SHASH_FOR_EACH:遍历SHASH这个map中的节点,将节点地址赋值给SHASH_NODE。
1 |
|
其他方法:
1 | /* 向 shash 中插入一个elem,插入时先做检查,如果已经存在,就返回false,不存在才添加 */ |
sset
A set of strings.
hash值是由name计算得到。
1 | struct sset_node { |
sset_add:添加一个字符串name到sset中,如果name已经存在,则返回NULL,否则返回新建的sset_node节点。
注意传递的字符串会进行拷贝,malloc 的大小是基于字符串的长度。
1 | struct sset_node * |
hmapx
A set of void * pointers.
在hmap上进行了扩展,实现了一个set。
hmap在使用时,往往是将hmap_node嵌入到某个结构体中,结构体是可以用户自定义的。而且该节点的key也就是hash值是用户指定的。
hmapx就没有hmap那样的通用性,hmapx_node就是上面描述的嵌入了hmap_node的结构体,该结构体只有一个成员void *data。另一个特殊在于节点的hash值不能指定,而是基于data的地址自动计算。
hmapx也可以看作key-value,key是void *data,value也是,所以不会存在两个节点相同,也就是实现了set。
1 | struct hmapx_node { |
hmapx查找是否存在某个data时,是通过直接比较data指针是否相等。
1 | struct hmapx_node * |
HMAPX_FOR_EACH:遍历hmapx中的每一个hmapx_node节点。struct hmap_node *NODE;
1 |
HMAPX_FOR_EACH_SAFE:与HMAP_FOR_EACH_SAFE类似。
1 |
hash
cmap
How Cuckoo Hashing Work Part 1 (Introduction to Cuckoo Hashing)
How Cuckoo Hashing Work Part 2 - Introduction to Cuckoo Hashing
Concurrent hash map.
实现不再是基于hmap,完全是另一套方式,最主要的特点是支持并发操作。
基本结构与hmap类似,也是一种哈希桶,mask和n的意义也相同。
1 | struct cmap { |
skiplist
lib/skiplist.h
lib/skiplist.c
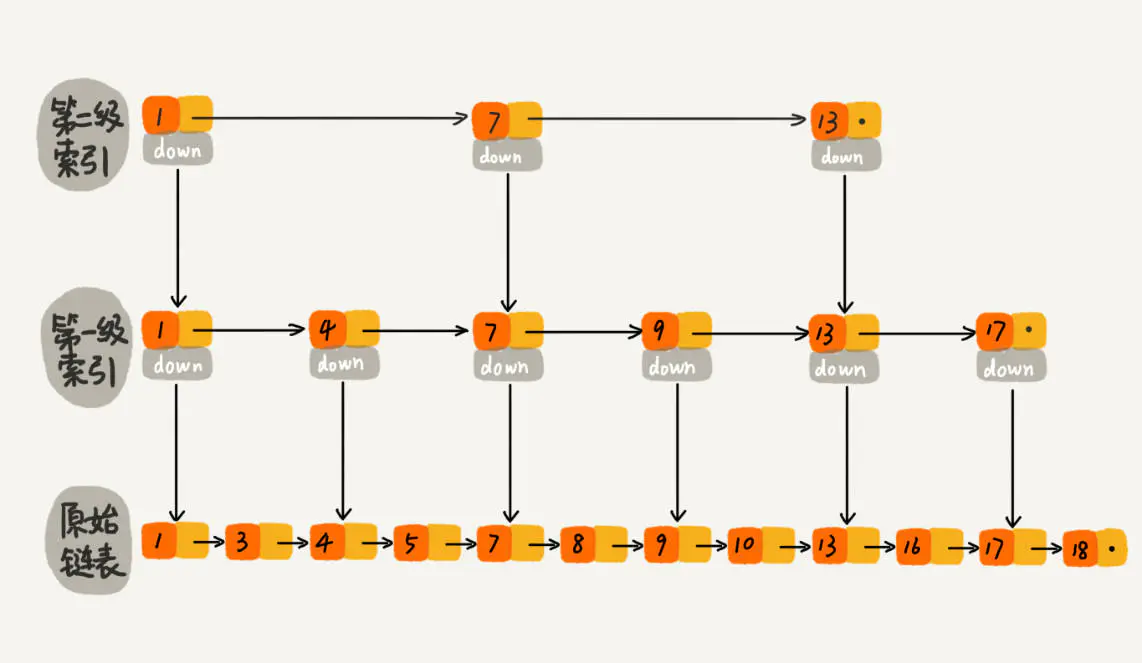
1 | /* Skiplist container */ |
pvector
lib/pvector.h
Concurrent Priority Vector.
优先级vector,支持并发操作。
1 | struct pvector_entry { |
ds
include/openvswitch/dynamic-string.h
动态扩容的字符串结构。
1 | struct ds { |
svec
lib/svec.h
字符串vector,可自动扩容。
1 | struct svec { |
svec中的字符串可能是无序的,提供了方法svec_sort对其按字典序排序(快排),调用其某些方法要求先对其排序。
pbytes
lib/byteq.h
General-purpose circular queue of bytes. 以字节为单位的循环队列。
1 | struct byteq { |
ovs-rcu
lib/ovs-rcu.h
原子指针变量可以很方便地实现一个无锁算法;但有一个大问题:当 writer 将这个针指向一个新的数据结构时,其他线程可能正在读旧的版本,问题是,当所有用到这个旧的版本的线程完成操作后,怎么 free 这个旧的版本!
1 |
ovs-thread
lib/ovs-thread.h
lib/ovs-thread.c
一次性初始化
在多线程环境下,某些初始化函数要求执行一次,并且也只能执行一次。所以需要一些机制来保证。
在pthread库中,实现了函数pthread_once(once,void (*init)(void))),其中once是一个静态变量,用于记录该初始化操作是否执行过,而init是进行初始化操作的函数。
ovs对此进行了一点扩展,或者说实现了一套类似的机制:
1 | struct ovsthread_once { |
poll-loop
include/openvswitch/poll-loop.h
这里也涉及到线程一次性初始化和线程特有数据,参见《Linux-Unix系统编程手册》第31章。
coverage
lib/coverage.h
lib/coverage.c
统计代码覆盖率(用于检查某段代码执行了多少次),可以看看gcov的例子,不过OVS中使用的coverage很轻量级,而且需要主动调用COVERAGE_INC才能进行统计。
json
include/openvswitch/json.h
lib/json.c
JSON 的两种结构:
1、对象:大括号 {} 保存的对象是一个无序的名称/值对集合。一个对象以左括号 { 开始, 右括号 } 结束。每个”键”后跟一个冒号 :,名称/值对使用逗号 , 分隔。
1 | { |
2、数组:中括号 [] 保存的数组是值(value)的有序集合。一个数组以左中括号 [ 开始, 右中括号 ] 结束,值之间使用逗号 , 分隔。
1 | { |
一个json对象中,数据是以key:value的形式存在的,key总是字符串"string",value是可以嵌套的,可以是:
- 数字(整数或浮点数)
"key" : 3.14 - 字符串(在双引号中)
"key" : "value" - 逻辑值(true 或 false)
"key" : true - 数组(在中括号中,多个
value)"key" : [3.14, 6, 7, 8] - 对象(在大括号中)
"key" : { "subkey": "subvalue" } - null,
"key" : null
在ovs中,json的value的结构为:
1 | /* A JSON value. */ |
value只可能是上面列举的几种类型之一,因此这里用union结构。并通过json_type指示value的类型,从而进行不同的操作。另外,对于逻辑值true/false以及null,只需要用json_type就足以说明,因此union中并不存在这三者的成员。
1 | /* Type of a JSON value. */ |
json数组中存储的值也都是一个value,分配内存采用了c++中vector这些容器类似的策略,先预分配n_allocated大小的容量,当实际在使用的数量n变大后,再扩容。
1 | /* A JSON array. */ |
这里分析的都是value,json对象里面不还有字符串key吗?其实已经看到了,只是比较隐蔽。
在上面的union中,json对象是用struct shash *object;表示,而shash(看看前面)是*a map from string(char name) to void *data,这里的name就是key,data当然就是指向struct json了。
创建value:
这里都是几种
value,严格来说它并不是json对象。因为它不能单独存在,没有key!。
1 | struct json *json_null_create(void); |
创建array类型的json对象:
这就是前面提到的
json的两种结构之一:数组。可以单独存在,哪怕是一个空的,序列化为字符串为:
如果其中有对象(不是上面的
value),序列化为字符串为:
2
3
4
{"key1": "value1"},
{"key2": 3.14}
]
1 | /* 创建一个空的 array 对象 */ |
创建object类型的json对象:
这是
json的另一种结构,一个完整的对象!如果为空,序列化为字符串为:
插入成员后,序列化为字符串为:
2
3
4
"key1":"value1" ,
"key2": 3.14
}
1 | /* 创建一个空的 json object 对象,是一个shash结构! */ |
创建json对象的其他方式:函数名已经说得很清楚了!
1 | struct json *json_from_string(const char *string); |
还提供了一些其他有用的方法:
1 | /* 将type转为字符串并返回,注意是 const char *,不能修改字符串的内容 */ |
const char *与char const * 效果一样,都是不允许修改指针指向的地址空间的值,即把值作为常量,而char * const则是不允许修改指针自身,不能再指向其他地方,把指针自己当作常量使用。需要注意的是,使用char * const 定一个常量指针的时候一定记得赋初始值,否则再其他地方就没法赋值了。
1 | /* 拿json实例计算hash值,该实例可以是上面的任何enum json_type */ |





