
Linux网络编程-网卡收包
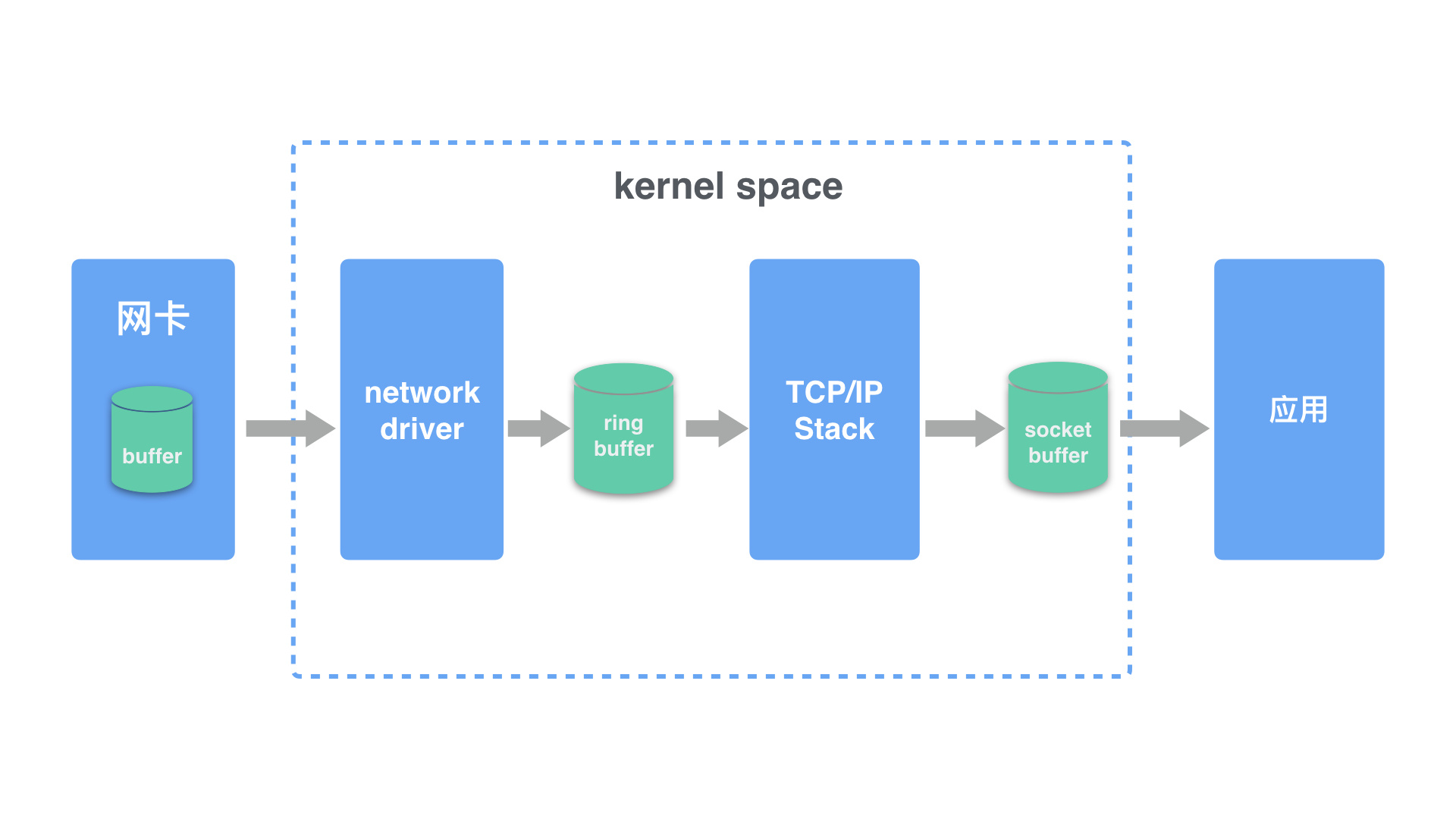
在开始之前,我们先用一张图解释 linux 系统接收网络报文的过程。
- 首先网络报文通过物理网线发送到网卡,
- 网络驱动程序会把网络中的报文读出来放到
ring buffer中,这个过程使用 DMA(Direct Memory Access),不需要CPU参与 - 内核从
ring buffer中读取报文进行处理,执行IP和TCP/UDP层的逻辑,最后把报文放到应用程序的socket buffer中 - 应用程序从
socket buffer中读取报文进行处理
注意图中的几个 buffer 缓冲区!
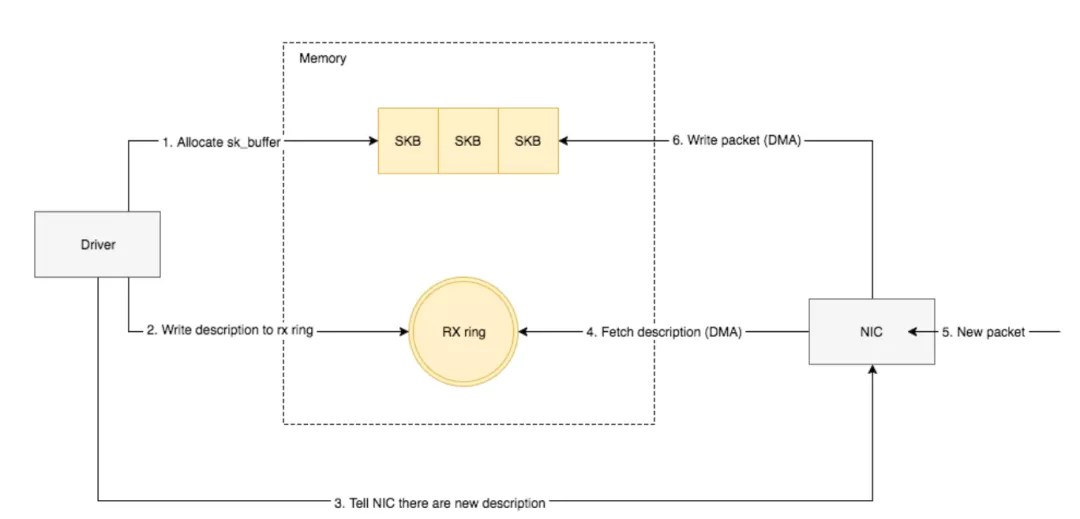
step1:网卡到ringbuffer
NIC 在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是 rx ring buffer。它是由 NIC 和驱动程序(内核)共享的一片区域,事实上,rx ring buffer 存储的并不是实际的 packet 数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做
sk_buffer; - 将上述缓冲区的地址和大小(即接收描述符),加入到
rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址; - 驱动通知网卡有一个新的描述符;
- 网卡从
rx ring buffer中取出描述符,从而获知缓冲区的地址和大小; - 网卡收到新的数据包;
- 网卡将新数据包通过
DMA直接写到sk_buffer中。
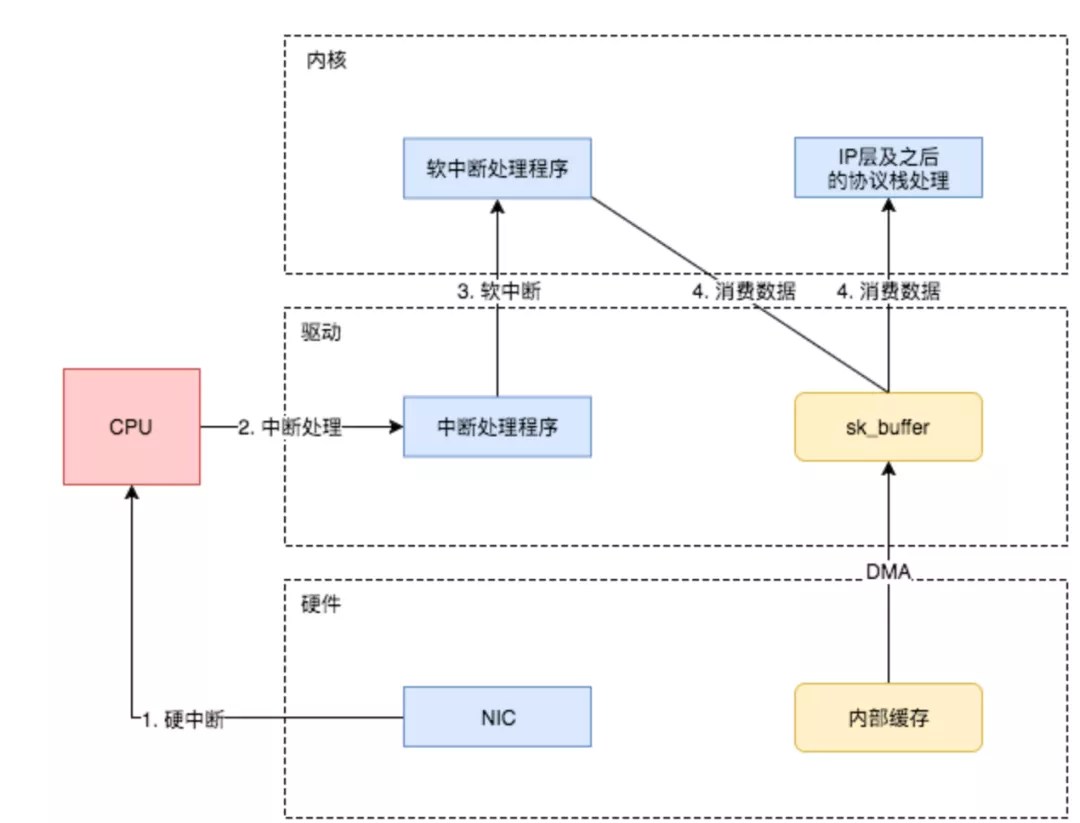
硬中断与软中断
内核和网络设备驱动是通过中断的方式来处理的。当设备上有数据到达的时候,会给CPU的相关引脚上触发一个电压变化,以通知CPU来处理数据。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)将过度占据CPU,将导致CPU无法响应其它设备,例如鼠标和键盘的消息。因此Linux中断处理函数是分上半部和下半部的。
上半部通过硬中断只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。剩下将绝大部分的工作都放到下半部中,可以慢慢从容处理。
下半部实现方式是软中断,由ksoftirqd内核线程全权处理。和硬中断不同的是,硬中断是通过给CPU物理引脚施加电压变化,而软中断是通过给内存中的一个变量的二进制值以通知软中断处理程序。
当 NIC 把数据包通过 DMA 复制到内核缓冲区 sk_buffer 后,NIC 立即发起一个硬件中断。CPU 接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费 sk_buffer 中的数据,交给内核协议栈处理。
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。特点快速执行;
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。特点延迟执行;
上半部分硬件中断会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 ksoftirqd/CPU 编号,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
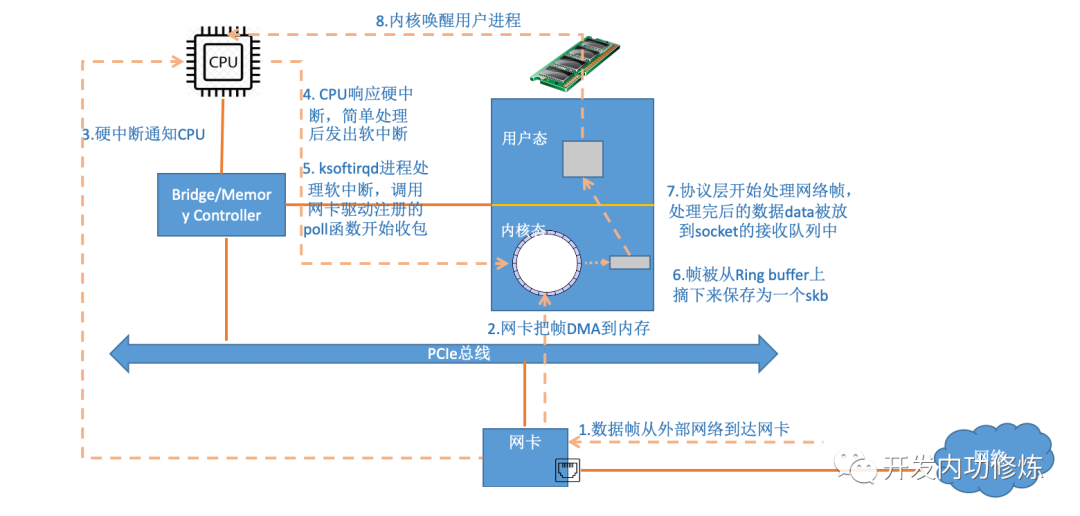
中断,CPU 能快速响应网卡的请求,但是大量数据包需要接收时,中断处理会降低 CPU 效率。
为了解决这个问题,现在的内核及驱动都采用一种叫 NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断 + 轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
网卡驱动
在Linux的源代码中,网络设备驱动对应的逻辑位于driver/net/ethernet, 其中intel系列网卡的驱动在driver/net/ethernet/intel目录下。协议栈模块代码位于kernel和net目录。
相关资料
《Linux 设备驱动 Edition 3》





